コンピュータ用語の中には日常聞きなれない単語があります。「リテラル」もそのような用語の一つです。リテラルとはプログラムの中で具体的な値を直接書いた時の、その値を指します。
int num = 10;
char moji = ‘A’;
return true;
英語の意味は「(意味が)文字通りの」、「事実に即した」、「融通が利かない」などで、「そのものズバリで、変化しない」といったイメージでしょう。
プログラムの中でのリテラルには数値リテラル、文字リテラル、文字列リテラルがあります。
各種リテラル
| 種類 |
表記 |
例 |
| 整数 |
10進数 |
先頭が(マイナス符号を含む)1~9で始まる0~9の整数、但し一桁の場合は0も可 |
-8
16 |
| 2進数 |
先頭が0b(又は0B)で始まる0及び1を使ったビット列 |
-0b1000
0b10000 |
| 8進数 |
先頭が0(8進数を表す文字記号)で始まる0~7の数列 |
-010
020 |
| 16進数 |
先頭が0x(又は0Xの16進数を表す文字記号)で始まる0~9及びa~f(又はA~F)の16進数列 |
-0x10
0x20 |
| 浮動小数点数 |
標準表記 |
10進数の実数(整数部、小数点、小数部) |
-8.0
16.0 |
| 指数表記 |
Eを底とする指数表記(仮数部、e(又はE)、指数部) |
-8.0e+0
1.6e+1 |
| 文字 |
シングルクォーテーションで1文字を囲う。文字はユニコードで規定される範囲。 |
‘a’
‘A’ |
| 文字列 |
ダブルクォーテーションで文字列を囲う。文字列内の文字はユニコードで規定される範囲。 |
“A”
“ABC” |
リテラルに対して、変化する値を扱うのが変数です。
メモリー上の特定の領域に名前を付けて、その名前でその領域にデータを記録したり、書き換えたり、参照できる。これが変数であり革新的なアイディアでした。プログラム言語はここから始まったといっても良いでしょう。
しかし、変数だけでは解決しない事がありました。それは変数の型です。
リテラルはその物のズバリの表現なので、コンパイラーはその表現に合わせ必要な記憶領域を決まることが出来ましたが、変数は単なる名前であり、メモリー上の番地を示しているだけです。コンパイラはどのくらいの記憶領域をそれぞれの変数に対して割り当ててよいのか分かりません。そこで、変数ごとに記憶するデータに合わせた型を宣言してもらう必要がありました。
変数の宣言
書式
データ型 変数名;
同一型の変数は「,」で区切り一行に複数書くことが出来ます。
但し、変数ごとのコメントは付けられないので要注意
データ型 変数1の名前, 変数2の名前, … ;
※
変数の宣言はC言語などオブジェクト指向プログラミング以前のプログラム言語では、プログラムの先頭で宣言するのが決まりですが、Javaではプログラムの可読性を上げるため、変数宣言は変数を使用する直前に行う事が推奨されています。
データ型
データ型はプログラム言語により(開発思想の違いから)若干の違いがあります。
Javaでは大きく基本(プリミティブ)型、参照型の二つに分かれます。
基本型は4種類、8型に分かれています。
| 種類 |
型名 |
ビット幅 |
備考 |
| 整数 |
byte |
8 |
|
| short |
16 |
|
| int |
32 |
リテラルのデフォルト |
| long |
64 |
|
| 浮動小数点数 |
float |
32 |
|
| doubl |
64 |
リテラルのデフォルト |
| 文字 |
char |
16 |
ユニコード1文字のみ |
| 真偽値 |
boolean |
– |
true/false(小文字のみ) |
※型名は小文字のみ
(C言語と比べた)Javaの型の特徴
–
数値と文字は型として独立している。
–
文字数(記憶領域サイズ)の確定している文字は基本型、文字数の確定しない文字列は参照型。文字列の内容が1文字でも文字列は文字列で、扱いは異なる。
–
真偽値が基本型として存在し、数値(0や1)での真偽値表現はしない。
データ型ごとのデフォルト値
| データ型 |
デフォルト値 |
| 整数 |
0 |
| 実数 |
0.0 |
| 文字 |
‘¥u0000’
(印字は半角の空白) |
| 真偽値 |
false |
基本型の変数は宣言によりメモリ上に記憶領域が確保され、デフォルト値で初期化されます。
但し、デフォルト値のままではコンパイルエラーになり、明示的な代入又は初期化演算子による初期値設定が必須です。
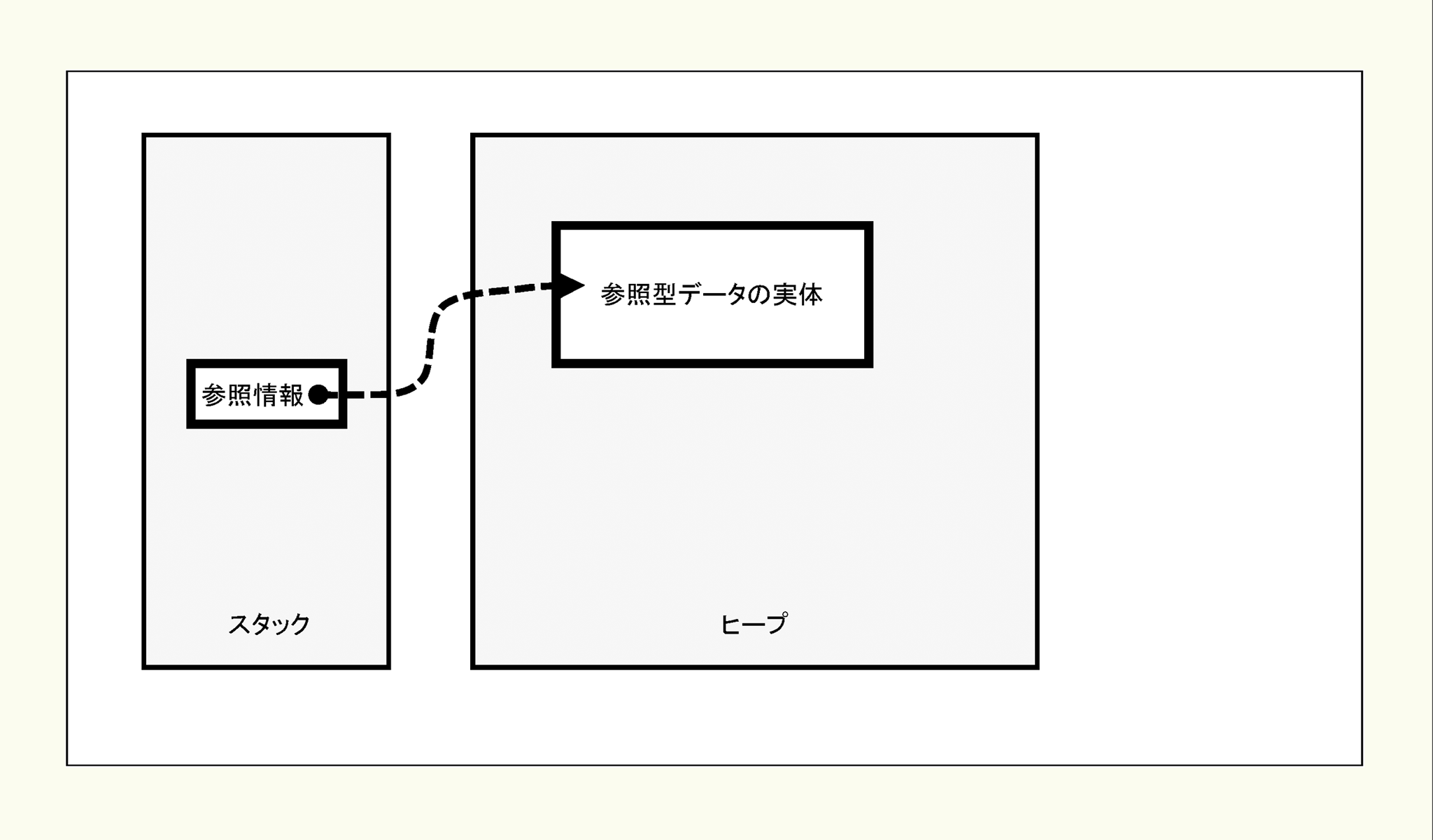
参照型は配列や文字列、オブジェクトなど構造を持ったデータの型で、記憶領域のサイズが個々に異なるためデータの実体と実体への参照情報をセットにしてデータを記憶します。また、サイズの決まった情報とサイズが任意の情報を効率よく管理するため、この二つの情報はJVMが管理するメモリ空間の中の別々の領域に記憶されています。
Javaは基本的にプログラマにメモリ管理を意識させない言語ですが、この参照型は記憶領域の確保法が基本型と異なるので、JVMのメモリ管理について少し詳しく見てみましょう。
参照型データの記憶
JVMの管理するメモリ空間には、管理方式の異なる領域がいくつかありますが、参照型データはスタックとヒープという領域を使って記憶します。
スタック(Stack)
線形のデータ構造で、プッシュ/ポップによる簡潔な管理の為素早いアクセスができます。
メソッドの実行順の制御情報、ローカル変数の基本型の値や参照型の実体参照情報を記憶します。
メソッドの再帰呼び出しなどでこの領域が一杯になると、JVMはStackOverflowErrorが発生します。
ヒープ(Heap)
アクセスは低速ですがガーベージコレクションを含めた複雑な管理が行われる非常に大きな領域です。クラスのインスタンス、参照型データの実体など動的なデータを記憶する領域でガーベージコレクションの対象になっています。なお、クラス構造やコンスタントプールなど静的なデータはピープの一部であるメソッド・エリアに記憶されます。
インスタンスや参照型データを大量に作成しヒープが一杯になると、JVMはOutOfMemoryErrorを発生します。
参照型データのメモリー上の配置
参照型データの実体はヒープ領域に確保され、ここへの参照情報がスタック領域に確保されます。
配列データの記憶
参照型データの一つである配列を使って、参照型データの情報がどのように管理されているか次のケースで見てみましょう。
1)
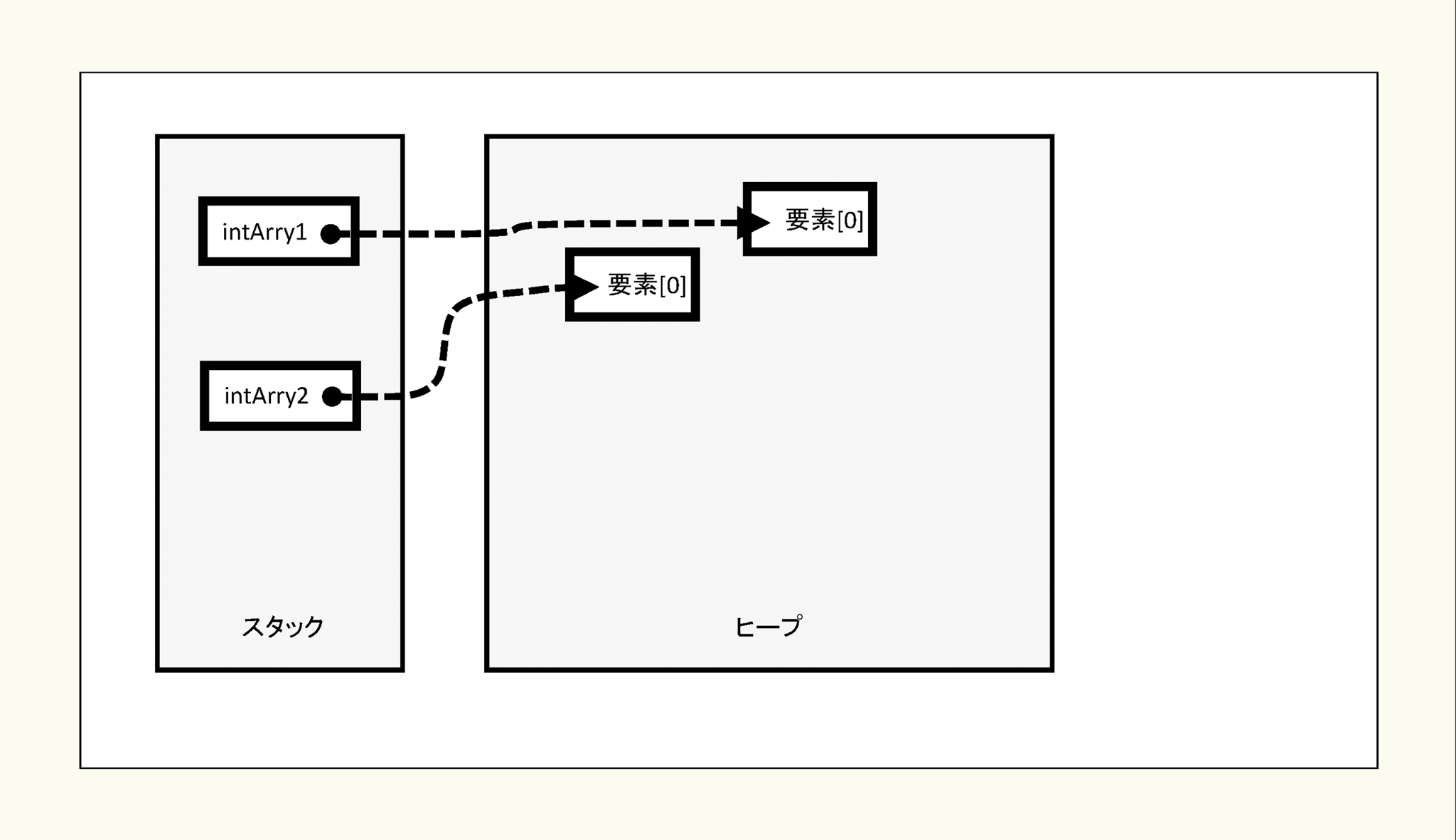
int型で要素が1つの配列を二つ(intArry1とintArry2)を作ります。
2)
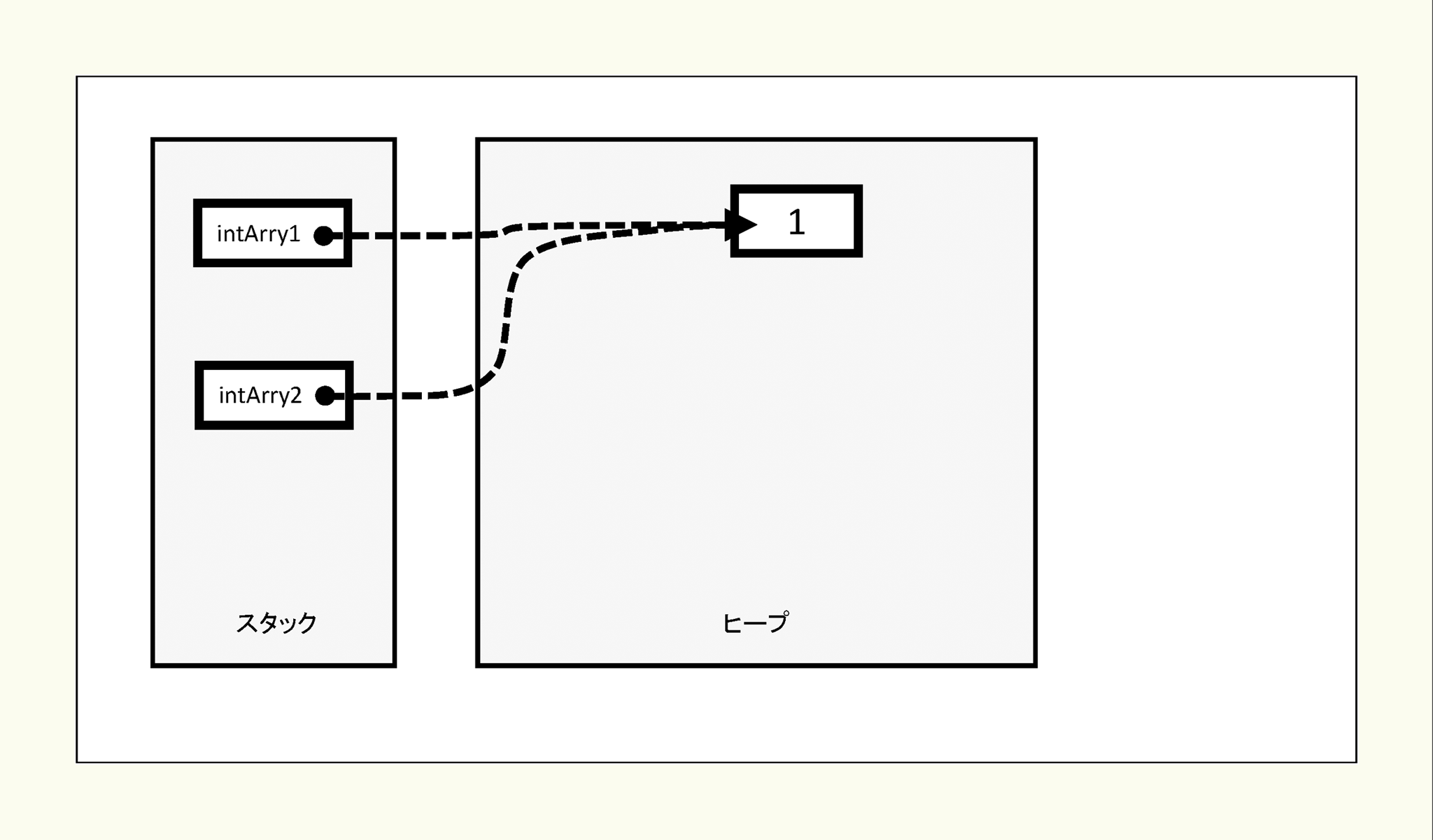
intArry1の配列変数(配列の実体を参照する情報)をintArry2の配列変数に代入します。
3)
intArry1の実体の内容を変更し、intArry2の内容はどうなるか確認します。
プログラム
class TestArray {
public static void main(String[] args) {
int[] intArry1 = new int[1];
int[] intArry2 = new int[1];
System.out.print("intArry1[0]=" + intArry1[0] + "\nintArry2[0]=" + intArry2[0] + "\t\t... 1"); // 1)
intArry1[0] = 1;
intArry2 = intArry1;
System.out.print("\nintArry1[0]=" + intArry1[0] + "\nintArry2[0]=" + intArry2[0] + "\t\t... 2"); // 2)
intArry1[0] = 10;
System.out.print("\nintArry1[0]=" + intArry1[0] + "\nintArry2[0]=" + intArry2[0] + "\t\t... 3"); // 3)
}
}
実行結果
>java TestArray
intArry1[0]=0
intArry2[0]=0 … 1
intArry1[0]=1
intArry2[0]=1 … 2
intArry1[0]=10
intArry2[0]=10 … 3
>
配列の参照経路と配列要素の内容変化
上記の各ケースにおいて参照型データの情報がスタックとヒープ間でどのように管理されているのか見てみましょう。
1)
intArry1、intArry2の実体用の領域がヒープに、そこへの参照情報がスタックに格納され、各配列の実体(唯一の要素である0番目の要素)にはint型のデフォルト初期値0が入ります。
2)
intArry2の配列参照情報にintArry1の配列参照情報を代入したため、intArry1もintArry2も同じ配列を参照します。このため、intArry2の要素には値を代入していないのに、整数リテラル1を代入したintArry1の要素と同じ値になっています。
3)
また、intArry1の要素の内容を変更すると、intArry2の要素の内容も同じ値に変ります。
以上のように、配列など参照型データは実体とその参照情報の組み合わせで管理されるため、その扱いには注意が要ります。
なお、参照型でもString型はプログラムの中で頻繁に使われる文字列としての扱いが更に加わるので、他の参照型データとは異なる独自の挙動を持っています。
プログラミングに戻る